Python 웹 크롤링 - Scrapy 활용 파워볼 번호 수집(파일)
Python 웹 크롤링 - Scrapy 활용 파워볼 번호 수집
1) scrapy 프로젝트 폴더 생성 및 gitHub 등록
1-1) vscode를 사용하여 scrapy 라이브러리를 통해 프로젝트 생성 및 git-hub에 소스 업로드 하여 관리한다.
- 위내용은 Windows Git 설치 및 GitHub 활용방법을 통해 확인 할 수 있다.
1-2) PowerBall 프로젝트 폴더 생성 및 git bashshell 에서 git init 명령으로 로컬 Repository 생성

1-3) gitHub에 원격 Repository 생성

1-4) git remote add 명령을 통해 gitHub의 원격 Repository 등록

1-5) git pull 명령을 통해 git hub에서 원격 Repository를 새로 생성 할때 만들어지 .gitignore 파일 및 README.md 파일 다운로드 후 로컬과 동기화.

2) Scrapy 프로젝트 생성
2-1) scrapy startproject PowerBall(프로젝트명) 명령어를 통해 프로젝트를 생성한다.
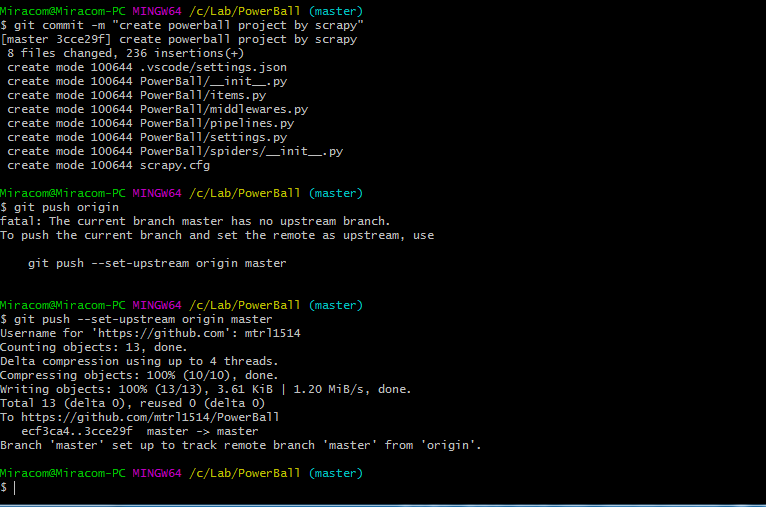
2-2) git add 및 git commit 명령을 통해 프로젝트 파일 커밋, git push를 통해 원격저장소로 등록
-add, status

- commit, push
3) 크롤링 목적 및 대상확인
3-1) 크롤링 목적 : 크롤링 공부
크롤링 대상 : PowerBall 당첨번호
필요데이터 : 추첨일, 회차, 당첨번호, 파워볼

4) Item 파일작성
4-1)파일목적 : 수집할 데이터 구조를 정의하며, 적절한 변수명으로 구분한다.



5-4) 크롬 개발자 도구 활요
- 크롬에서 F12를 누르면 개발자 도구 창이 열리 는데 개발자 도구를 통해 spider 코딩을 위한 xpath를 쉽게 알수 있다.


5) Spider 파일 작성
5-1) 파일목적 : 데이터 수집 절차에 대한 수행 코드를 작성한다.
5-2) 파일위취 : spider 폴더 내 신규 파일로 생성 한다.
- powerball_spiders.py 이름으로 신규파일 생성
5-3) 작업철차
- 해당 웹페이지에서 추출하고자 하는 정보들의 위치를 파악
- 추출하고자 하는 정보 구조 파악
- 정규표현식을 이용하여 확보한 전체 웹페이지 정보 중 필요 데이터맘 추출


5-4) 크롬 개발자 도구 활요
- 크롬에서 F12를 누르면 개발자 도구 창이 열리 는데 개발자 도구를 통해 spider 코딩을 위한 xpath를 쉽게 알수 있다.

6) Pipelines 파일작성
6-1) 파일목적 : 수집된 데이터 처리 방식 정의(파일저장/DB/이메일발송등)
6-2) 확인사항 : 한글 처리를 위해 저장할 파일에 대한 utf-8 설정 필요

7) Settings 파일 작성
7-1) 파일목적 : 프로젝트 모듈간 연결 및 기본 설정 정의

8) 크롤링 실행 및 결과
8-1) 크롤링 실행
>>scrapy crawl PowerBall

8-2) 크롤링 결과


이게 왜 빠른거죠? 나눔로또한페이지가 많은 정보를 보여주고 있어서그런가요 아님 thread 병렬처리가 들어 가는건가요? 수자 올라가는걸 봐서는 thread 병렬처리는 아닌것 같은데.
답글삭제